
K-Puzz: Algorithms in Action
September 17, 2025
I've always liked puzzles, from Sudoku to games like Antichamber. Rarely it seems that if there's a particular puzzle I really enjoy, there is an abundance of it around to keep me satisfied. On top of that, ideas always pop up for how to tweak the puzzle rules to make it more interesting or more difficult. That's one of the joys of writing software, it gives me the ability to make those ideas come to fruition.
Kjarposko puzzles, abbreviated "K-puzz", were created by Kjartan Poskitt as part of the Murderous Maths book series. This is an example of a case where I wish there were more Kjarposko puzzles from the official source. I've never seen these types of puzzles outside of the Murderous Maths book I had as a kid.
In making what is effectively a clone of K-puzz, I wanted to use this opportunity to refine my full-stack skills. The complexity that arises from the interactive elements of puzzles and games yields a set of challenges that are different from a typical full-stack application.
The Setup
I didn't plan on changing the rules of K-puzz at all. The innovation instead comes from the way the puzzles are implemented on a web application and the accompanying UX. I wanted the puzzles to be programmatically generated on the fly and to be random. Typically, self-contained logic puzzles similar to K-puzz or Sudoku are hand-crafted and the data for each individual puzzle are stored on a database. I don't want to manually write hundreds of puzzles (and if I needed to, I'd probably come up with a method to programmatically generate them anyways). This allows for an effectively infinite pool of puzzles with almost no storage required. Of course, being able to go back to previous puzzles played is a must-have feature, so the puzzle generation needs to be repeatable.
In pursuit of improving my skills, I decided to use React for the front end. I already had some experience with React, however not in the area of interactivity required by K-puzz. This gives me an excuse to dive further into the React ecosystem, as well as understand how to incorporate it with the back end into a full-stack project.
Generational Representation
I started by working on the front end. In order to get the UI working, I needed to come up with a structured data format to represent puzzles. The format should be able to represent every possible puzzle by swapping out the specific data used.
Kjarposko puzzles can be uniquely represented by an N by N+1 matrix, where N is the number of boxes in the puzzle. All matrix representations follow the same format as shown below: the first N columns form a binary square matrix that represents the connections between boxes, and the last column contains all of the top values in the puzzle. Each row of the matrix represents a box, the 1's show which boxes contribute their bottom values to its top value. Yes, it is possible to solve a K-puzz by constructing this matrix and computing its reduced row echelon form, but where's the fun in that?
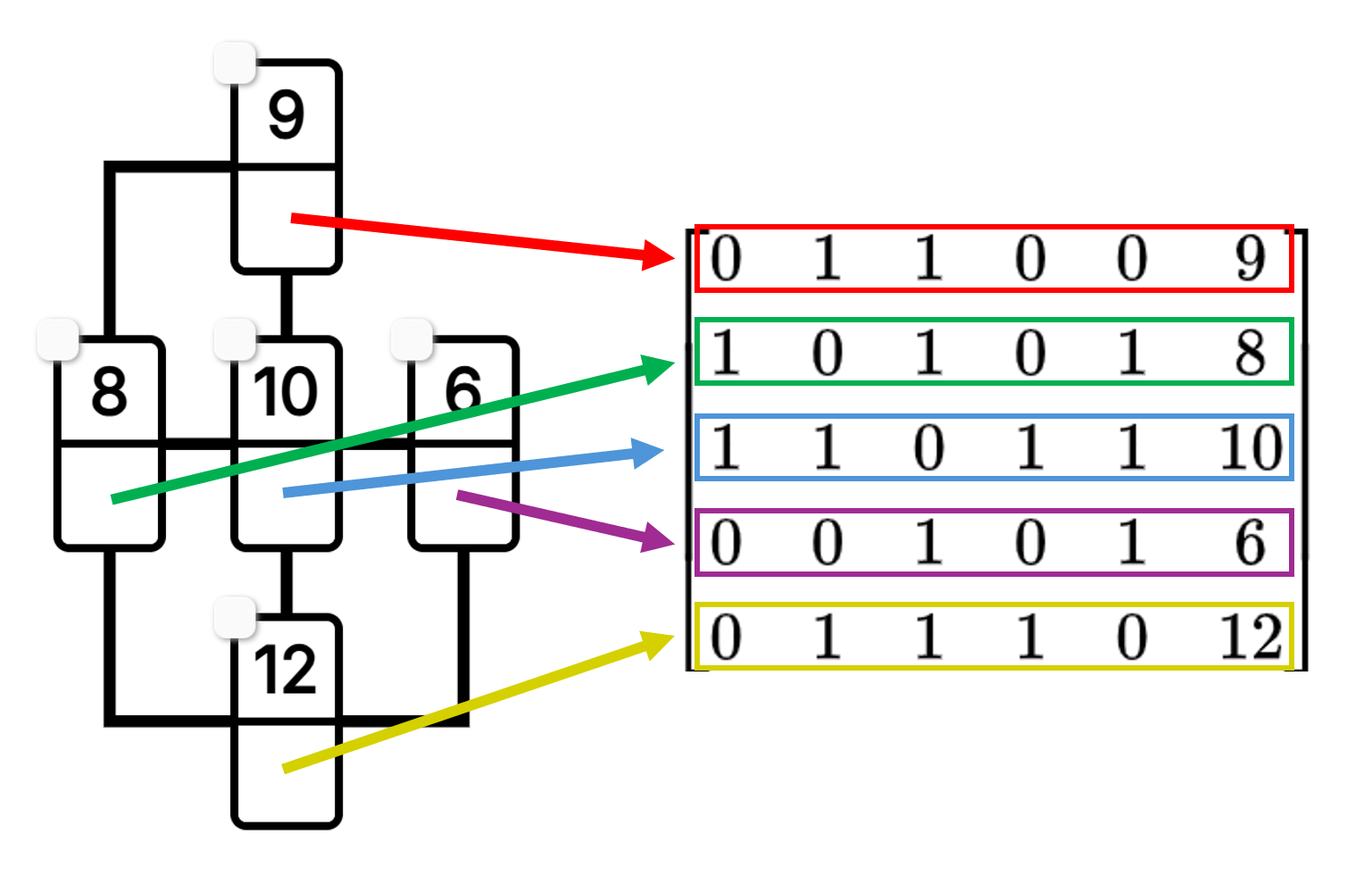
The problem with the matrix representation of a puzzle is that it doesn't capture the exact position of the boxes or connections. So, either the matrix representation needs to be augmented to include position values, or an entirely new representation will have to be created.
The Start of Something
Writing an algorithm for puzzle generation was a significant challenge. There was a lot of trial, error, and iterative design when creating a function to randomly generate a valid puzzle. The final algorithm I settled on starts by placing the boxes in the puzzle, then creates the connections between boxes, and finally uses those connections to calculate the values in the boxes.
To get into specifics, given some width 'W' and height 'H' for the puzzle to be generated, a W by H square grid of empty boxes is created. Each box then has a 25% chance to be removed from the grid. For each remaining box, there is chance to create a connection to all nearby boxes. The chance that a connection is formed decreases with the Manhattan distance between the two boxes being connected. After all boxes have been iterated over, a second pass is made over all boxes to add connections to isolated or single-connected boxes. Finally, for the N boxes in the puzzle, the numbers 1 to N are shuffled and randomly assigned to the bottom of each box. Based on the connections formed, the top number for each box is calculated from the adjacent bottom numbers.
But What Makes a K-Puzz Valid?
There are two restrictions on forming connections between boxes: connections can't intersect and can't pass through boxes. These restriction are put in place as there is no simple way to visually distinguish any overlapping elements in a two-dimensional image. As boxes and connections are formed during puzzle generation, any grid spaces occupied by them are considered "blocked". If all possible paths from a box must pass through a blocked grid space, then no connections from that box are considered valid, and thus none are formed.
Separate from individual connections, a K-puzz is valid if it has a unique solution and no isolated boxes. From a high-level design perspective, there should always be a singular chain of logical reasoning steps that lead to the puzzle's solution. Not having a unique solution creates ambiguity, which is bad UX as the user has no way of knowing whether any ambiguity comes from puzzle construction or their own lack of reasoning. Isolated boxes are disallowed as they don't share any information with the other boxes in the puzzle, so in many cases, there would be no way of knowing what number should be placed in the bottom of an isolated box. (What would the top number be in a box with zero connections?)
While connection generation guarantees that all connections are valid, the puzzle generation algorithm doesn't guarantee that a puzzle has a unique solution or that there are no isolated boxes (as it may be impossible to form any valid connection from an isolated box). If this happens, the puzzle is thrown out and a new one is generated from scratch.
Finding the Right Path
Writing an algorithm to find a path between boxes was challenging in a subtly different way than the puzzle generation algorithm. With puzzle generation, the difficulties came from the large number of restrictions on different components of a puzzle and balancing the importance and random chances of different puzzle features. When it comes to efficient pathfinding, the problem to be solved is much simpler, but much more difficult.
Phrasing the problem statement as a list of specific, absolute requirements makes it appear to be astronomically difficult. However, a little bit of ingenuity goes a long way. The key is to not think about connections or boxes that could block a potential path, but to recognize that all grid spaces occupied by a connection or box are equally "blocked". By applying strict upper and lower bounds on the grid coordinates that a path can occupy, the pathfinding problem becomes identical to the classic algorithms problem of finding a minimum length path through a grid with obstacles. Practicing Leetcode questions helped me recognize that the pathfinding problem could be solved using a breadth-first search.
It's Always JSON Isn't It
This is the point where the data format for puzzles becomes relevant. The puzzle generation algorithm outputs a list of boxes, where each box is a collection of simple key-value pairs, and a list of connections, where each connection is a list of ordered tuples. This information wholly represents a puzzle. Using the matrix representation of a puzzle would require some complex math in order to construct it, and as mentioned earlier, is inadequate as-is. I decided to combine the lists of boxes and puzzles into a JSON compound. The JSON schema is consistent, and can be easily parsed using native JavaScript methods, making it a suitable structured data format for representing puzzles.
Repeatable, Repeatable, Repeatable
To make previously generated puzzles playable, I opted to assign each puzzle a unique ID. The ID is based on the timestamp at generation. Looking for an application of back-end functionality, I decided to store the stringified JSON of each puzzle in a SQL database along with its ID. Whenever a puzzle is started, if no ID is provided by the user, a new puzzle and ID would be created and written to the database. If the user enters an ID, the database is searched for that ID and the puzzle data is retrieved.
The scope of what the back end needs to do is comparatively simple, so I elected to use Express for the server and Node to communicate between the front end, back end, and database. Using Node and Express, there's much less overhead than with complex frameworks. This also allows the full app to be written entirely in JavaScript. For the database I used PostgreSQL, as it's an industry standard for full-stack applications.
This combination of technologies works, all the features I wanted to include in K-puzz are there. However, this is not the most practical solution. There were a few issues that immediately came to mind. Firstly, each new puzzle requires an HTTP request and either a database read or write operation. These operations are very standard and typical, however for the scale at which I'm running this application, anything that isn't strictly necessary is impractical. Second, the database can grow very quickly, taking up large amounts of storage. Each time a new puzzle is generated, a new record is created. Users can (and should) rapidly click through puzzles to find one that looks appealing. Storing every puzzle and ID gives a complete history of all puzzles that have been generated. This satisfies the repeatability requirement, but is very much overkill.
Identifying a Better Solution
What if there was a way to translate between unique IDs and puzzle data? This would eliminate the need for a database entirely, and if the translation is done on the client, also eliminates the need for a back end. Puzzles are still repeatable, and timestamps can still be used to generate IDs. The solution I came up with was to use the puzzle ID as the seed for the random number generator. While JavaScript PRNG isn't truly random, it simulates random events well enough for the purposes of K-puzz.
There is one problem with this approach, the same ID gives different results for different combinations of puzzle dimensions. While the user can reliably generate the same puzzle with the same ID if they remember its dimensions, this isn't ideal. I plan to integrate information about the puzzle's dimensions into generated IDs in a future update.
Given that this system is much simpler, I elected to use it for the live demo. The original goal for this project was to refine my full-stack skills, so the code for the full-stack implementation of K-puzz is still available in the associated GitHub repo.
Reality is Difficult
As a relatively early full-stack project of mine, K-puzz isn't the best application ever made. While the code is functional, there is definitely room for refactoring and improvement. Having the puzzle generation, including pathfinding, run on the client is potentially computationally taxing, especially on lower-end systems.
Another missing feature that impacts UX is the lack of a difficulty setting. High variance in difficulty arises from the random generation of K-puzz. In order to evaluate the difficulty of a puzzle, there would need to be a way to precisely calculate a difficulty metric from its data representation. Going the other direction, for a user to be able to select a particular difficulty, that metric would need to influence the puzzle generation algorithm. The difficulty of each puzzle arises from the specific logical techniques used to solve it. In order to include a difficulty metric in puzzle generation, the logical techniques needed would need to be captured by the data representation of a puzzle, i.e., that data format would also need to include a precise chain of logical reasoning steps that lead from an empty puzzle to a solved puzzle. Currently, the data format used doesn't support this. I can't say with certainty that creating a puzzle representation that includes a logical path to a solution is impossible, however, this would be an extremely difficult task, especially as there often isn't a single way of finding a puzzle's solution.
Regardless, the final project works and is feature complete, given my initial idea for K-puzz. There are also some extra features I'd like to add that would improve UX.
Future Plans
There are several improvements I want to make to K-puzz in the future. Most importantly, I want to incorporate information about the width and height of puzzles into IDs, so that the same ID will always yield the same puzzle, regardless of the dimensions set. In addition to puzzle IDs being handled through the UI, I would like to include them as query strings in the URL as well. This allows puzzles to be shared through URLs, which is a bit more user friendly than copying and pasting IDs into text boxes. This goes hand0in-hand with the next improvement I'd like to make, I want the results from completing a puzzle to be sharable via a URL. Lastly, and most simply, I want to add a pause button that stops the timer.
Even without any of these future plans implemented, I am satisfied with K-puzz. All the features I wanted from the start are present, and the current state surpasses what I would consider a minimum viable product.
Similar to my experience building SET, my skills with React, Node, and Express significantly improved by making K-puzz. Additionally, I learned many new techniques for creating effective UI/UX. But in my opinion, what's much more valuable is that I have a deeper understanding of what there is to learn in the web development space.
K-puzz has a live demo available! Also, check out the included links below.